

据了解,2023年7月,依图发布了智能安防领域首个可实战可商用的多模态大模型—依图天问1.0。发布至今,依图天问大模型基座已完成了两次迭代升级,并率先在全国50多个项目中部署应用。
近日,在第十届中国(上海)国际技术进出口交易会上,依图科技最新版本的“依图天问大模型4.0”正式发布,以全新的交互体验、超高的进化能力,重新定义了多模态大模型在智能安防领域的应用边界。
此次发布的依图天问大模型4.0实现了众多功能的跨越式升级:融合自然语言与视觉信息,大幅提升视频内容的模糊检索能力;支持多条件组合场景布控,实现精细化布控和风险管理;依图天问4.0升级后的预训练模型支持算法极少样本冷启动,通过Agent代理辅助训练,真正实现了“想法既算法”的智能飞跃。
视频理解更细微,语义检索更丰富
语言交互的模糊性来源于语境的多样性。依图天问4.0引入多模态视觉搜索技术,将自然语言与视觉信息融合,以“用户”为主,深刻理解语境中的细微差别,例如:当需要搜索“骑电动车带多个煤气罐”的视频内容时,用户只需用日常语言描述需求,系统便可呈现出最贴近意图的搜索结果。同时,还可以针对视频内容里细小目标做模糊化检索。这些能力极大地提升了城市管理者日常运营和决策调度中的工作效率,降低了沟通成本。
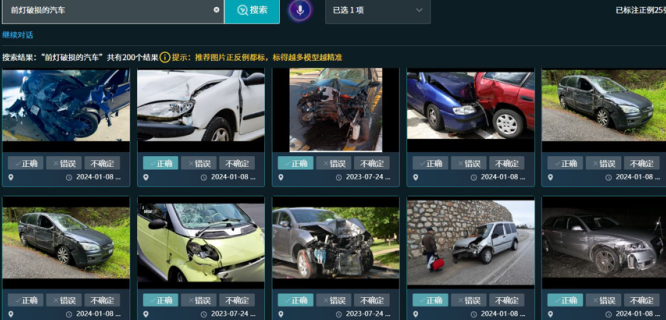
(上图示例:“前灯破损的汽车”,系统不仅能理解抽象的描述,还迅速反馈出精确的图像结果)
全要素理解、多条件布控更全面
高精度的视频内容理解,解锁了复杂视频场景布控的可能。机器可以代替人去看视频,像人一样看"懂"视频,对视频内容进行全场景、全要素的理解,就可以对典型的场景目标和规则进行精准布控,提前预警潜在风险,科学高效地辅助决策。依图天问4.0支持多条件组合的场景布控,可帮助管理者进行精细化风险防控和管理。在城市管理、环境监测、公共安全等领域,这项技术展现出极高的实战应用价值。
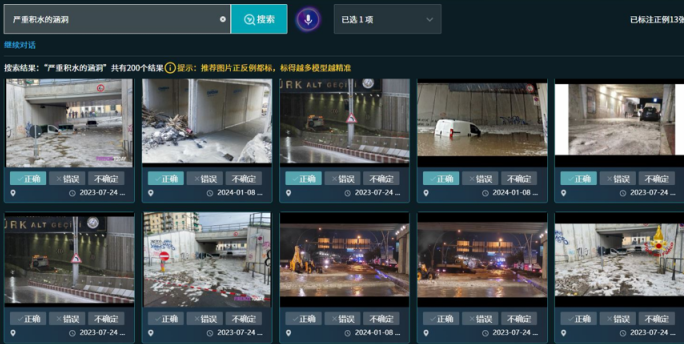
(上图示例:城市摄像机对“严重积水的涵洞”的历史事件进行搜索的结果)
样本更少更高效,现场训练更灵活
智能系统的一大特征是可以根据环境和需求的变化快速适配。传统的机器学习模型面对新的算法任务,需重新收集数据、训练模型,至少要1-3个月。依图天问4.0升级了预训练模型,可实现1分钟内对极少样本的新算法进行冷启动,1小时内完成在线标注训练,1天内快速部署上线。通过日常工作过程中快速积累的数据飞轮,操作人员每天花几分钟对齐数据、简单点击对错,几天时间就可让算法达到超过90%的准确率,展现出前所未有的智能化和灵活性,充分满足业务系统的敏捷性和管理的时效性。
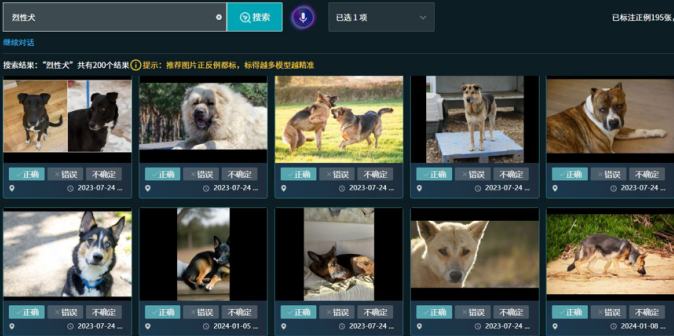
(上图示例:排查“烈性犬”,少样本对齐烈性犬,吉娃娃、拉布拉多、田园犬则极少出现)
想法即算法,Agent辅助更智能
Agent(代理)在多模态大模型体系里扮演着至关重要的角色。AI Agent能够基于历史交互记录和现有的算法能力,做出更为精准的决策辅助。依图天问4.0可辅助逐步对齐认知,解构重组算法。例如:当我们想训练一个“大型仓库里的小型叉车”,Agent会针对“大型仓库”和“小型叉车”的语义做对齐,从而使得用户的想法可以快速转化为直观的算法,让用户的每一个想法都能即时转化为直观的操作指令,实现“想法即算法”的飞跃,呈现出工作助手、智能体的灵动与高效特征。
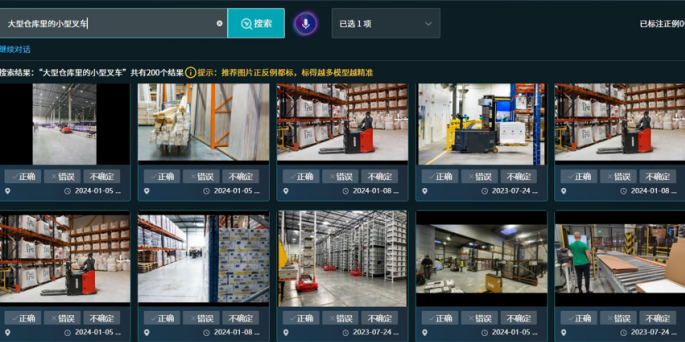
(上图示例:训练“大型仓库里的小型叉车”,Agent对“大型仓库”“小型叉车”的语义做对齐)
AI新时代,因为看见,所以相信!
2019年起,依图就开始了以Transformer为基础的大模型研究与应用探索。2020年,依图推出预训练语言理解模型ConvBERT,通过全新的注意力模块,仅用 1/10 的训练时间和 1/6 的参数就获得了与谷歌BERT模型一样的精度,相比OpenAI的 GPT-3,可用更少时间去探索语言模型的训练,也降低了模型在预测时的计算成本。2023年7月,依图天问多模态大模型正式发布,快速在全国项目中部署应用。
依图天问多模态大模型的工作范式,从传统深度学习的像素标注升级到了多模态大模型的表征对齐,通过视觉与语言模型的深度融合,归一了物理世界和认知世界的底层框架,构建起物理与认知世界的桥梁,实现了用户需求与技术创新的完美对接。此次发布的依图天问4.0在类人交互、情境理解、认知进化等方面再次迭代出新特点,提升了多模态大模型对复杂视频内容的理解和发现能力。
依图求索新十年,在垂直视觉领域,随着工程化应用逐步落地,内容理解的复杂度不断提升,目标特征、关系特征、空间特征、行为特征、统计特征、知识特征、业务推理不断解锁。而多模态大模型在理论基础上的不断突破,让我们也看到解锁更多应用场景的可能。
我们坚信,在智能安防领域,多模态大模型将发挥出更大潜能,尤其是在个性化需求强烈、环境多变的复杂场景中,将展现出更大的商业和社会价值。基于数据与算力的智能化运营将成为公共安全和城市治理的新常态,各行各业也必将随着技术的突破性发展真正迈入人工智能的新时代。
- 上一篇: 萤石网络发布双频千兆路由器,为家庭网络提供全方位保障!2024-06-18
- 下一篇: 罗格朗荣获2024阿拉丁神灯奖-数智奖,助推品牌高质量发展!2024-06-18
- · 长虹AI家电亮相第五届消博会,探索智慧生活新范式!
- · 云米智能烟灶套装,重新定义现代厨房体验!
- · 云米科技接入DeepSeek大模型,开启智慧生活新范式!
- · 涂鸦智能发布SMB解决方案,让空间照明更"懂"用户!
- · 康冠科技荣登全球移动智慧屏出货量全球第一,重新定义智慧生活!
- · 德施曼开展智能锁行业首届导购大赛,推动行业服务标准升级!
- · 萤石荣登“全国产品和服务质量诚信承诺企业”榜单,打造诚信市场环境!
- · 容声505/515方糖冰箱登场,重新定义健康美学!
- · 卡萨帝智能锁亮相广交会,树立行业发展新标杆!
- · 海信发布垂类智能体,助力AI产业化进程加速!
 说说
说说













